About
Serverless Scraping ⛏️
Have you ever run into websites which show something cool interesting and you would like to see more of it but don't want to actually bother to remember the page to go back. This is what happened to me and the reasoning behind this project. Web Scraping is often used for places which do not offer proper programmatic solutions, like APIs or RSS feeds. The way the technology works is a serverless Lambda function (which is just some code that runs on the cloud) will request the page just like any regular browser. However, it will then read over and parse the data. At which point a script can exact parts I find interesting. Then to finish up the function will connect to my a PostgreSQL database and save the good bits. That is the basics of the function to collect the data. This ends up looking a lot like a regular API, which is not by accident, the intention is to make the data from a website into a more programmatically consumable source. Then at last to complete project, I wanted convenient way to see the data. There are an infite ways you can do this, phone apps, websites, or desktop applications, really anything you can imagine.
async function getUpComingMovies() {
const html = await axios.get('https://www.imdb.com/calendar')
.then(res => res.data)
.catch(() => console.log('bad request'))
const dom = new JSDOM(html)
const main = dom.window.document.querySelector("#main")?.innerHTML
const data = {}
if (!main) return
await Promise.all(main.split('\n').map(async line => {
if (line) { // only read lines with content
if (line.includes('<h4>')) { // date
const text = line.replace(/<[^>]+>/g, '').trim().replace(/ /g, '_')
data[text] = []
} else if (line.includes('<a')) { // movie
const lastDate = Object.keys(data)[Object.keys(data).length - 1]
const partial = line.split('>')[1]
const title = partial.substring(0, partial.length - 3);
const href = 'https://www.imdb.com' + line.split('"')[1]
let img = ''
const arr = data[lastDate]
console.log('+', title, '| img =', !!img)
arr.push({ title, href, img })
data[lastDate] = arr
}
}
}))
return data
}
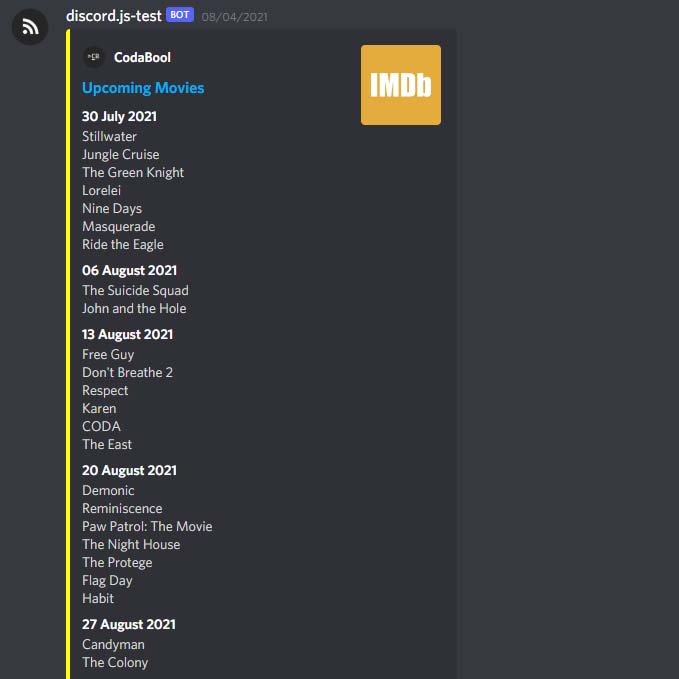
How I ended up using it 🤖
I was able to get data from several sites that I found interesting. But now I had a different issue of how I would like to be viewing the data. Discord offers many different SDKs will full API coverage. I wrote a bot in both JavaScript and later again in Golang. This allowed me have scheduled posting the scrapped data viewable in a table like format.
Issues I encountered 😤
I built the technology entirely using the AWS platform and the entire process is automated. I have rewrote this from JavaScript to Golang. I also used to use the Serverless framework to deploy the Lambda but switched it to Terraform. However, I do run into plenty of issues. Serverless is a large community project and goes through versioning as well as forks. I ran into issues with correctly setting up a API Gateway for my Lambda. I ran into issues with webpack since I first opted for ES6 code with conversion. In the end I cut Webpack due to it being too much overhead and too tricky to configure.
Then there was the AWS issue that I wanted to build the scraping technology also on lambda and triggerable through an endpoint. For endpoints like the trending-npm-1. I have multiple pages which are scraped and then compiled. The issue is not that the lambda timesout, it can run for up to 15 minutes as of 2021. The issue is that requests to API Gateway max out at 30 seconds. This means you should be responding within 30 seconds, which is reasonable. This did mean I needed to rewrite my application to comply with this timing, since some scrapes went on for nearly 50 seconds. Essentially I needed a lambda which would que another lambda and when that background lambda would finish it can have the first lambda send out a signal that it succeeded. This seemed too cumbersome and pointless. If all I was going to be getting was a '200 Ok, I'll tell a function to scrape'. I might as well have it be a crontab on a server and no api interface. This level of friction with the technology led me to compromise. I shortened every scrape function so it fit within the 30 second timeout. I do have the functions which scrape behind a password to prevent a monster bill. But the code is still viewable on github.
